


Most systems programmers are not new to creating and applying custom memory allocators in performance or memory constrained projects. However, the benefits of purpose-built memory allocators are often underestimated or overlooked by many programmers. This article aims to provide an overview of the motivation and advantages of deploying custom memory allocation schemes and presents a few common allocation strategies.
Just as with any other custom component that ought to replace a readily available general component, implementing custom memory allocators is often viewed as a symptom of NIH syndrome. That may be true in some cases, but such skepticism commonly stems from the false premise that the goal of writing a custom memory allocator is to create an objectively better general-purpose allocator. While that’s an admirable goal, especially for academia, the real goals of using custom memory allocators in a software project are usually far more modest yet better motivated, as we will see when we start exploring the objectives. But first, let’s start with clarifying what we really talk about here.
Nomenclature
When we talk about custom memory allocators in the context of application development what we really mean is a component that enables partitioning an operating system or runtime environment provided memory allocation into multiple smaller pieces, sometimes referring to such components as sub-allocators. This distinction between allocators and sub-allocators is irrelevant in practice, as technically even the operating system kernel memory allocator is actually a sub-allocator as it sub-allocates the physical memory and/or virtual address space available on the system.
What this means from a practical perspective is that a memory allocation request made by the application software to the runtime is actually served by a hierarchy of memory allocators and adding a custom memory allocator to the software means inserting yet another into this hierarchy, as depicted below:

User code may use runtime provided heap allocator, OS kernel provided allocator, or custom memory allocators built on top of either of these.
Each allocator in the hierarchy is responsible to sub-partition a partition reserved by an allocator below it, thus in worst case if there’s no more room for a new allocation in any of the already reserved partitions at any level of the hierarchy, each allocator needs to request a new partition from the allocator below it, potentially all the way down to the page allocators provided by the operating system.
In addition, most modern allocators provided by the runtime and operating system themselves are usually comprised of multiple different allocation algorithms operating in tandem to be able to serve different types of allocations (think of e.g. different allocation sizes) in an efficient manner.
It is also worth noting at this point that the use of custom allocators isn’t limited to sub-partitioning system memory allocations, one can use the same components to sub-partition other types of memories, persistent storage, or really any continuous addressable range.
Generally speaking, an allocator usually provides the following set of operations:
- Allocate – reserves a sub-partition of the address range
- Deallocate – frees a previously reserved sub-partition of the address range
- Resize (optional) – grows or shrinks a previously reserved sub-partition of the address range
The last operation is not common as in many cases it is difficult or impossible to implement it (at least efficiently), but we mention it here as some use cases may rely on support for it as we will see later.
Objectives
The most common goals of implementing custom memory allocators are the following:
- Improved performance of the operations provided by the allocator
- Improved memory efficiency by reducing internal and/or external fragmentation
- Improved performance through better spatial locality of related data and thus more efficient use of processor caches
However, recall that we’re not trying to beat the runtime or kernel provided allocators at their own game. Rather, it’s about knowing more about the allocation pattern of our software and thus being able to create a purpose-built allocator that may have functional limitations, may have worse performance or memory efficiency in the general case, but has better characteristics in the specific usage pattern our software employs.
General-purpose allocators provided by the runtime have to fulfill all sorts of requirements, including but not limited to the following:
- They need to be able to allocate sub-partitions of arbitrary size, ranging from a single byte up to gigabytes or more
- They need to be able to bookkeep arbitrarily large number of sub-partitions
- They need to be able to serve allocation and deallocation requests in virtually any sequence
- They need to be able to simultaneously serve requests from different threads
- They need to be memory efficient, thus they often cannot pre-allocate large partitions to speed up subsequent sub-partition allocations
This is why they work reasonably well in all scenarios, but complying to all of these requirements comes at a cost.
Contrarily, in case of memory allocations needed by a specific software component we may have additional contextual information that can enable us to do better, e.g.:
- We may know that we only need sub-partitions of a specific size or a specific set of sizes
- We may know that there is an upper bound on the number of sub-partitions to ever exist at a given time
- We may know that allocations and deallocations follow a specific pattern/sequence
- We may know that we will only allocate sub-partitions on a specific thread or sets of threads
- We may know the upper bound on the memory needed by all sub-partitions and we’re happy to reserve all of it up-front
Implementing custom allocators thus allows us paying only for what we actually need/use, and this is why a custom memory allocator can often effortlessly beat even the best general-purpose allocators in the context of a particular piece of code.
Now that we have the right premise, let’s see a couple of common memory allocation strategies and techniques that aim to increase allocation/deallocation performance.
LIFO allocator
Yes, we’re talking about a stack. While almost all programming languages provide a built-in stack to store local variables, function/method parameters, etc., they usually limit such allocations to objects whose size is known at compile-time. One notable exception is the C99 standard that supports variable-length arrays that can serve as backing store for dynamically sized objects on the stack. There are also other mechanisms provided by runtimes to dynamically allocate memory on the stack (e.g. alloca and _malloca) but usually they have their own set of quirks, thus usually it’s better to implement a LIFO allocator with a backing store allocated from the heap.
It’s no surprise that a LIFO allocator comes handy in similar situations as a stack, i.e. when an allocation matches some scope within the call hierarchy, and is often used to bypass the programming limitations to allocate memory for dynamically sized scope-local objects.
Implementing such an allocator is extremely simple: only a backing memory range and a stack pointer is necessary. Allocating and deallocating thus is constant time and trivial, as it only involves incrementing and decrementing the stack pointer, respectively.
It is easy to note that the basic implementation of this allocator requires all the memory that is available for sub-partitioning up-front and remains allocated for the entire lifetime of the allocator, and that the total size of the sub-partitions reserved at any given time cannot surpass this capacity. This, however, does not have to be the case. There are two common strategies to relax these restrictions, if needed. The first one is to follow the same solution that the built-in stack uses.
Nowadays application developers rarely have to mess around with the stack size configured for the application or its threads, but back in the days before virtual memory was a thing one had to pay attention to it, as making it too big consumed too much physical memory while making it small left the door open for stack overflow errors. While memory is still something that we don’t want to overcommit on, default stack sizes are usually extremely large yet they only consume as many physical memory pages as needed, thanks to runtimes only allocating virtual address space for the stack and back them with physical pages on demand. The same strategy can be employed by a custom LIFO allocator.
This still requires knowing the absolute upper limit for the size of the partition though. One could think that a runtime/kernel allocator supporting resize operations would be able to solve the problem of needing to increase the size of the partition, but that’s not the case in practice. While resize operations may as well be implemented with the same mechanism, i.e. allocate and commit further memory at the end of the partition, there’s no guarantee that the address space is actually available at the time of the resize, as other partitions may be using it. In such cases resize operations typically reallocate the virtual address range corresponding to the partition at a different location with sufficient contiguous address space, however, that’s usually unacceptable from the perspective of a custom allocator as it would invalidate all previous sub-partition addresses, unless the old address space is preserved as well which isn’t usually the case and can easily proliferate into significant virtual address space waste after multiple resize operations.
Another approach is to simply maintain a chain of partitions in the LIFO allocator and allocate a new partition every time a new allocation request arrives that doesn’t fit in the existing one. This can be thought of as a two-level stack (stack of stacks), where the first-level stack holds the backing partitions and the second-level stacks hold the sub-partitions. One drawback of this approach is the possibility of internal fragmentation, thus the size of the individual allocations made by the allocator should be selected appropriately to minimize that.
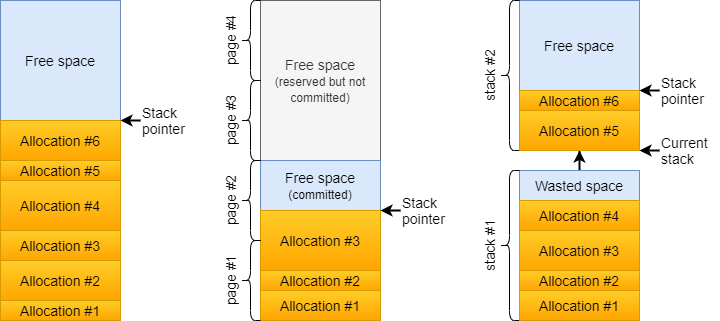
Obviously, there are additional non-trivial costs involved in these cases to commit physical pages to the pre-reserved virtual address range or to allocate additional partitions in a two-level stack, so not all allocations will get away with the trivial constant time cost of updating the stack pointer. Thus it’s always a balance between memory usage, performance, and flexibility and the appropriate variant should be chosen based on the needs of the application code in question.
Same applies if we want to decommit pages or deallocate partitions if the stack shinks sufficiently and we want to free up memory, and is generally advised to not do so unless necessary, as it can cause continuous grow/shrink costs if the stack pointer keeps moving around the boundary. Therefore it’s better to always keep around some amount of additional free space (committed pages or additional partitions) to avoid such pathological cases.
FIFO allocator
This type of allocator comes handy when partitions are allocated in the same order as they are deallocated. This enables treating the backing partition as a queue where an allocation request is treated as data being pushed at the front and deallocation is treated as data being pulled at the back. Thus all the tracking that is necessary is a head and tail pointer, therefore allocation and deallocation is constant time and as trivial as incrementing the head and tail pointers, respectively.
FIFO allocators are very useful for allocating transient objects, a common example being software components operating as non-branching pipelines where the sub-partitions provide the storage for the input and output data of the pipeline stages.
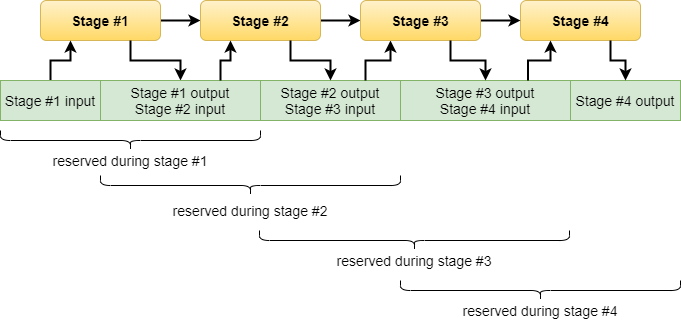
If the maximum required memory isn’t known up-front then the same approaches presented for the LIFO allocator can be used to reserve additional pages or partitions for more memory, though the same caveats apply as well.
In addition, in case of FIFO allocators there’s sort of a third option as the back of the partition becomes progressively free as sub-partitions are deallocated, thus allocation can be performed in a round-robin fashion by treating the parition as a circular buffer. In its simplest form this may cause fragmentation at the end of the partition if the next allocation no longer fits there thus has to be reserved at the beginning. This, however, can be avoided by allocating twice the amount of virtual address space for the partition and mapping the physical memory to both halves of this address space. In such a setup allocating a continuous sub-partition is always possible as we bridge the gap between the end and the beginning of the partition’s physical memory.
By using the mechanism above the partition sub-allocated by the FIFO allocator needs to be only as big as the maximum memory needed by any single stage of the pipeline.
FIFO allocators can also be used to serve branching pipelines by using a separate FIFO allocator for each new branch forked. If we would like to avoid that, the FIFO allocator can be extended to support allocations and deallocations to be issued in arbitrary sequence, and thus enable it to serve parallel branches simultaneously, however, that has the following implications:
- Deallocation of a sub-partition that isn’t the backmost live allocation will be delayed until it is, thus deallocation may not happen immediately
- Additional tracking is necessary to accomplish that which comes at a performance cost
Again, it’s always a trade-off between memory usage, performance, and flexibility.
Size constrained allocators
As you probably already see the pattern, the performance benefits of custom allocators usually comes from taking advantage of certain constraints we impose on the flexibility of the allocator compared to a general-purpose one. The examples presented so far limited the order in which allocation and deallocation requests can follow each other. This time we look at custom allocators that limit the size of individual sub-partitions instead.
It’s quite common for certain software modules to frequently allocate/deallocate instances of the same type of object that have a specific size. Such an allocator is typically referred to as a pool allocator or memory pool.
It is surprisingly simple to construct a custom allocator that is able to serve allocation/deallocation requests of such objects in constant time by pre-allocating a memory partition suitable to hold a certain number of such objects simply by maintaining a singly linked list of available entries that we pop from on allocation and push to on deallocation.
Such a custom allocator can be trivially extended to support arbitrary number of such objects by having a two-level singly linked list where the first-level list contains the non-full partitions and the second-level list contains the individual slots available. Of course, the usual caveat applies that if we want to support the number of partitions to dynamically grow or shrink then we still have to issue partition allocation/deallocation requests to the underlying memory allocator, but most requests can be still served in constant time.

One thing to keep in mind when implementing a pool allocator is that it is generally better to keep the linked list control structure separate from the actual object slots to keep the slots uniformly aligned and contiguous in memory for better processor cache utilization.
That also brings us to the next thing that may come up in the use case scenarios of object pools whereas often user code needs to allocate multiple slots at once and preferably they should be contiguous in memory, in fact sometimes that’s a must have. Supporting such additional requirements complicates the allocation scheme and generally allocations can no longer be served in constant time as partically we’re pretty much back to the problem of a general-purpose allocator just one that has a specific granularity. Although, as in such cases you’re actually allocating memory for multiple objects at once, the additional cost of going with a more sophisticated allocation scheme is technically amortized across the number of objects instantiated.
It’s also worth to take the opportunity here to talk about multi-threading. In case of pool allocators implemented with such singly linked lists it’s possible to extend it to support allocation/deallocation requests coming from multiple threads by using lock-free linked lists instead, and usually there are lock-free thread-safe solutions for most allocation schemes using atomic operations. Still, the usual principle of paying for only what you really need applies here as well, thus such solutions should only be employed when concurrent allocation/deallocation is actually a requirement.
Another typical option to support serving multiple threads is to use separate allocators per thread though obviously that’s a trade for improved performance at the cost of additional memory usage due to each thread’s allocator now maintaining its own partition or set of partitions it sub-allocates from.
The linked list based approach isn’t the only common implementation for memory pools. Often a simple bit-array based tracking works just as well, sometimes even better. While the time complexity of allocations is linear in the number of slots in this case, crunching through a contiguous range of memory is extremely efficient on modern processors due to the optimal use of the caches, and with a single 64-bit read we can easily check the availability of 64 slots at once. This is ofttimes the preferred implementation approach when support for reserving multiple slots in contiguous memory is preferred or required, as finding contiguous slots and reserving them can be quickly done using bit masks.
It is rarely the case that a single pool allocator supporting objects of a single size is enough. In this case one can use multiple pool allocators for each object size in need, although that also comes at the cost of additional memory usage, just like using separate allocators per thread.
Instead, it’s possible to create a pool allocator that allows serving requests with more than just one size from the same partition(s). This clearly must have a performance cost, although, with a well constructed solution the cost can be limited to the logarithm of the number of different sizes needed to be supported. This leads us to another common allocation strategy that is also used by operating system kernels for large-scale sub-allocation: the buddy allocator.
The buddy memory allocation algorithm is an allocation scheme where usually a power-of-two sized partition is successively split into halves to try to give a best fit. The control structure is pratically a binary tree where each subsequent level contains nodes representing the first and second half of the memory region of their parents. In the standard implementation allocations and deallocations are served in logarithmic time, where the upper bound is the binary logarithm of the depth of the tree, i.e. the number of times the partition can be successively split into two.

Strictly speaking, buddy allocators can only allocate/deallocate chunks in power-of-two multiples of the minimum block size, however, it can also be used as a general-purpose allocator of arbitrarily sized chunks with the caveat that in such uses this allocation scheme exhibits significant internal fragmentation.
Implementations usually use an array representation of the binary tree for efficiency which can be statically allocated knowing the partition size and the minimum allocation size that we plan to support. Similarly to earlier allocators, dynamic capacity can be supported by maintaining a linked list of such trees, though the use of nested trees isn’t uncommon either.
Count constrained allocators
We’ve already seen in all of our previously presented allocation algorithms that knowing the total size of allocations enables room for certain optimizations like allocating the backing partition up-front, and that knowing the size or set of sizes of allocations allows us to employ simpler and more efficient allocation schemes than what a general-purpose allocator has to be prepared for.
Another constraint on the usage pattern that can enable writing more efficient memory allocators is when we know the total number of allocations that can exist at any given time, as this grants us the ability to lay out our control structures in a fixed-size container, possibly in ways that are more processor cache friendly.
We’ve seen a few examples of this already, as the single partition variants of the pool allocator and the buddy allocator are similarly count constrained allocators while also being bound by size constraints. But here we will take a look at an example that focuses strictly on constraining the maximum number of allocations.
As an example, if we would like to support N allocation blocks in a partition where the free and allocated blocks are maintained using linked lists, then we know that there will be at most a total of 2*N+1 number of nodes in these lists at any given time (maximum N allocated blocks with free holes between them, and two more free blocks at the beginning and end of the partition), and the available node entry indices (nodes not being linked to any of the bookkeeping lists) can be maintained on a simple stack implemented using a fixed-size array.
This, contrarily to traditional linked list based general-purpose allocators, provides the benefit that there isn’t a need to add headers/footers to the allocated sub-partitions thus accessing allocations may allow for better processor cache utilization and potentially lower fragmentation in case allocations have to conform to specific alignment requirements that would otherwise cause the blocks to straddle due to the headers/footers, and, as a bonus, they are less prone to control structure corruption in case of buffer overflows/underflows.

The count constrained variant uses separate control structure (block node array and unused node stack).
Notice how headers/footers can cause alignment imposed straddle (unavoidable free block between the two aligned allocations), and that the presence of headers/footers may result in sub-optimal use of cache lines for small allocations.
In case of a simple first-fit allocation policy, this allocation scheme allows for the typical allocation time complexity to be constant time with a linear worst case, and constant time deallocation, just like its unconstrained variant. However, due to the control structure being separate, the linear worst case is usually still faster in absolute terms due to better chance of cache hits while traversing the list of free blocks.
Just like unconstrained linked list based allocators, their count constrained variant can also employ binning free blocks based on their size to support best-fit or approximate best-fit allocation policies, but the advantage is, once again, that the corresponding control structures have a strict upper bound on their size, so we can statically allocate them and lay them out in a cache-friendly fashion, which fully generic solutions wouldn’t be able to do.
Still, before jumping to early conclusions that this is objectively a better allocator, don’t forget that we made compromises to achieve these benefits. First, the number of allocations is limited. Second, because there’s no mapping from the allocation’s address to the corresponding control node, we have to keep around the block node index along with the allocation’s address in order to be able to free a block in constant time. In fact this is typically the case with count constrained custom allocators, and the only reason we didn’t need to do so in case of pool allocators and buddy allocators is that those use fixed block sizes, thus the block index can be directly derived from the allocation’s address.
Conclusion
Implementing custom memory allocators is no silver bullet, but if applied in the right scenarios it can be a great item on the tool belt of any software engineer. This article mainly focused on improving performance through the use of custom memory allocators, but some of the presented ideas can also be used to reduce memory usage.
We’ve seen that the benefits of using custom memory allocators are stemming from the implementation freedom enabled by constraining the problem space at hand compared to the general-purpose allocators provided by runtimes and operating systems that are mostly one-size-fits-all solutions (though usually using multiple different specific algorithms internally). As it can be universally acknowledged about programming, everything is a trade-off between run-time performance, memory usage, and flexibility, and usually the means through which custom memory allocators achieve their goals is by sacrificing the latter.
We’ve presented some of the most commonly used custom memory allocators, and a few ways to customize them. It is important to recognize, however, that this article is in no way tried to provide a complete list of common custom allocators (if such a thing is even possible), or to suggest that any of the presented custom allocation strategies would improve the performance of a given piece of software.
As always, optimizations should be applied where there’s value in doing so. Once it is known with certainty that memory allocation/deallocation is a performance bottleneck, and the code (or design) is sufficiently analyzed to understand the usage pattern of dynamic allocations and their rationale, only then it is time to consider using custom memory allocators.
Even then, it’s quite possible that a simple “cookie-cutter” custom allocator, as some of the ones presented here, is not the right or the best solution for the problem at hand. Often the best approach is to derive a set of constraints from the analysis of the dynamic allocation usage pattern of the code in question, and construct a tailor-made allocator for it. That’s where, hopefully, the ideas and examples showcased in this article should be able to help.
Finally, we must remember that the best kind of dynamic allocation is no dynamic allocation at all, so if the storage for some data can be statically allocated without unreasonable memory usage or flexibility consequences then that’s probably the best thing to do.